How to Become a Site Reliability Engineer
Are you looking to transition your career from another role and become a site reliability engineer? Or maybe you’re just starting out and trying to get into this role. Either way, you’re in the right place. Today we’ll discuss these topics.

- What’s site reliability engineering (SRE) all about?
- Who is a site reliability engineer (also called an SRE for short)?
- What’s the difference between DevOps and SRE?
- What skills must you have to become an SRE?
So with no further ado, let’s get started.
What Is Site Reliability Engineering?
SRE combines software engineering practices with IT engineering practices to create highly reliable systems. Site reliability engineers are responsible for the reliability of the full stack, from the front-end, customer-facing applications to the back-end database and hardware infrastructure.
An SRE has responsibility for all these areas:
- General systems uptimes
- Systems performance
- Latency
- Incident and outage management
- Systems and application monitoring
- Change management
- Capacity planning
When software development became faster and more complex, traditional software teams started having trouble keeping up. They introduced DevOps, which helped with the transition of workflows from development to production applications.
But something was still missing. The industry needed people who could increase the reliability and performance of this system. And this is where site reliability engineering comes in. Benjamin Treynor (now Benjamin Treynor Sloss) introduced the concept of the site reliability engineer back in 2002.
What Is SRE?
—Benjamin Treynor Sloss, founder of the SRE team at Google
Ideally, SREs are engineers who have software engineering experience as well as Unix systems administration and networking experience. These individuals also have polished programming skills. That’s because SREs routinely use automation to reduce human labor and increase reliability.
SREs participate in development duties about half the time. They spend the other half doing operations duties, such as responding to outages and incidents and being on call at times.
How Things Have Changed
Historically, software engineers would design code. Then they would hand it over to IT operations to deploy, maintain, and respond to incidents regarding their code.
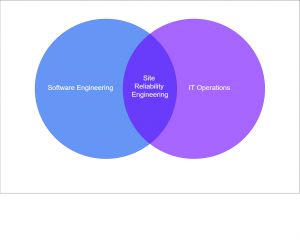
The SRE role lets software engineers play a part in how people and teams deploy and maintain software. It also lets them improve software to increase system reliability and performance.
Site reliability engineers are now able to oversee software and performance of the full technology stack. That means they can identify and resolve issues more easily and efficiently than the traditional development and operations team. The SRE role is ultimately responsible for maintaining systems’ uptime and reliability.
How Can SREs Achieve Success?
How can an SRE ensure they are delivering software faster than before and maintaining systems uptime and performance? Site reliability engineers must monitor all components of the product or system. Since this could be a very large task, SREs identify and measure a set of key reliability metrics to help them pinpoint the most important tasks and identify weak areas. These metrics include cservice-level indicators, service-level objectives, and service-level agreements.
DevOps vs. SRE
After reading all this, you must be thinking that SRE is similar to DevOps. It is, but only to an extent.
As we discussed, the developer traditionally developed the code and sent it to the IT operations team to manage, maintain, and deploy. The developer wanted to release code more often, and IT operations was concerned about downtime of the application. These two teams needed to align to ensure they released more quickly and ensure the code released became more reliable.
Today, SRE and DevOps work together to bridge the gap between development and IT operations. DevOps implements agile software development practices to increase automation, reduce downtime, and scale beyond the traditional teams.
Both DevOps and SRE embrace risk and accept failures. DevOps releases small changes more often, and the SRE reviews the DevOps methods and monitors progress. They share a unified goal of releasing more often, without errors and downtime. The critical difference is that the SRE implements DevOps methodologies. In turn, the SRE defines how to implement DevOps practices and actively participates across the development and operations teams. When team members work together, it’s a beautiful thing.
Now that you know more about the overall responsibilities and duties of an SRE, let’s get into specific skills.
Skills Required to Become a Site Reliability Engineer
Well, everyone’s path is a little different. But there are some common things that just about all successful site reliability engineers need to know.
Skill 1: Knowing How to Code
Because of the nature of the SRE role, understanding development and coding can go a long way.
Now, which language does it make the most sense to learn? Since day-to-day tasks of an SRE include automating processes and dealing with systems, knowing Python, Go, or Java can help you in the long run.
Skill 2: Understanding Operating Systems
Working with servers at a large scale can be a bit stressful. Having a thorough knowledge of your organization’s operating system (usually Linux or Windows) is necessary. As an SRE, you’ll be working with these operating systems regularly.
Skill 3: CI/CD
Implementing DevOps practices is what differentiates the SRE role from the DevOps role, but both roles have things in common. Continuous integration/continuous deployment is one of them. To be a top-notch SRE, you need to be able to build a CI/CD pipeline from scratch for any application.
Skill 4: Using Version Control Tools
As a software developer, while working with code, you’ll be using Git or some other kind of version control tool. So it makes sense to learn about version control tools. The best way to accomplish this is to learn Git and GitHub.
Skill 5: Using Monitoring Tools
Monitoring tools make your life easier when you’re an SRE. They give you a brief look into your system performance and issues your system is dealing with. Implementing these tools and getting insights from them is the primary goal of SRE, so the system experiences as little downtime as possible.
Prometheus and Grafana are widely used monitoring solutions, so it makes sense to learn those.
Skill 6: Gain a Deep Understanding of Databases
Learn about so-called NoSQL databases. There are many types, and each has pretty specific use cases where they excel. Compare and contrast with relational databases like MySQL. This is an excellent time to dive into understanding what a data model is, why data models are necessary, and how the data model should inform your choice of database and your service architecture.
Skill 7: Make Your Life Easier With Cloud Native Applications
Knowing cloud native applications is another way to make your life easier in this line of work. You don’t have to know them in depth, but here are some knowledge areas that can help your organization and you as you get on the road to becoming a successful SRE.
- Having some idea about how containers work
- Knowing what Docker is
- Understanding how to run a secure application using Kubernetes
Skill 8: Master Distributed Computing
Knowing how distributed computing works and understanding the concept of microservices are both significant advantages for an SRE. You’ll be handling large, distributed systems, so having some experience with these topics can really help you get ahead in this career.
Skill 9: Improve Your Communication
As an SRE, you’ll often be on call with the chief executive officer, chief technical officer, or with your manager, depending on the size of your company. You’ll need to report critical incidents that affect applications. Even when you aren’t on call, you’ll be working with software engineers and others. In all these situations, having effective, well-developed communication skills makes life much easier. For example, you can make sure there are no miscommunications while reporting incidents.
Where Can You Learn These Skills?
So, we’ve covered a long list of things an SRE needs to know. Let’s see where you can learn many of these skills.
Have a look at these outstanding resources to get you started. These are all from Cprime.
Coding: Mastering Python Programming
CI/CD: Implementing a CI/CD Pipeline
Microservices: Microservices Engineering Boot Camp
Databases: Introduction to MongoDB for DBAs
Version control: Git and GitHub Boot Camp
Docker: Docker Containerization Boot Camp
Kubernetes: Introduction to Kubernetes
All these links may seem overwhelming. But keep one thing in mind: You don’t need to master every single aspect of every area we covered today. Knowing a little about many topics will be fine, as long as you are eager to learn.


