An Introduction to Apache Kafka
In 2016, RedMonk described the “rise and rise” of a powerful asynchronous messaging technology called Apache Kafka. Now—more than three years later—Apache Kafka is still on the rise as a very popular distributed messaging system.
The Big Data industry grows daily and needs tools that can process enormous volumes of data. That’s why you need to know about Apache Kafka, a publish-subscribe messaging system that you can use to build distributed applications. It’s scalable and fault-tolerant, making it ideal for supporting real-time and high volume data streams. Because of that, large internet companies like LinkedIn, Twitter, Airbnb, and many more use Apache Kafka.
So, at this point, you probably have questions. What value does Apache Kafka add? And how does it work? In this post, we’ll explore the use cases, terminology, architecture, and functioning of Apache Kafka.
What Is Apache Kafka?
First, let’s talk about what Apache Kafka is and how it works.
Kafka is a distributed publish-subscribe messaging system. It has a robust queue that can accept large amounts of message data. With Kafka, applications can write and read data to topics. A topic acts as a category for labeling data. Next, an application can consume messages from one or multiple categories.
Kafka persists all the data that it receives to disk storage. Then, Kafka replicates data within a Kafka cluster to prevent data loss.
Kafka can be very fast for several reasons. First, it doesn’t offer many bells and whistles. Another reason is that Kafka does not have individual message IDs. It uses the offset of when the message was received. Also, it doesn’t track the consumer for a topic or who has consumed a particular message. Consumers interested in this data should track this information.
Upon data retrieval, you can only specify an offset. Then, starting from that offset, Kafka will return you the data in order. There are plenty more speed optimizations available with Kafka, but we won’t cover them in this post.
All of these optimizations allow Kafka to handle large loads of data. But to get a better understanding of the capabilities of Apache Kafka, we need to first understand the terminology.
Apache Kafka Terminology
Let’s discuss some of the terms that are key to know when working with Kafka.
Producer
A producer generates large amounts of data and pushes this to Kafka.
Consumer
A consumer can be any type of application that reads data from the queue.
Topic
Kafka allows you to label data under a category called a topic. Consumers can subscribe to specific topics they want to read data from. On the other hand, producers can write data to one or more topics.
Partition
A topic can have multiple partitions to handle a larger amount of data.
Replicas of partition
A replica is a partition’s backup. Apache Kafka aims to be a resilient messaging system, so it needs to have backups. Kafka prohibits reading or writing data to replicas. Replicas simply prevent data loss—they don’t have any other responsibilities.
Messaging System
A messaging system transfers data between applications. This allows an application to focus on data, rather than on how data gets shared. Instead, the messaging system must decide how to share the data.
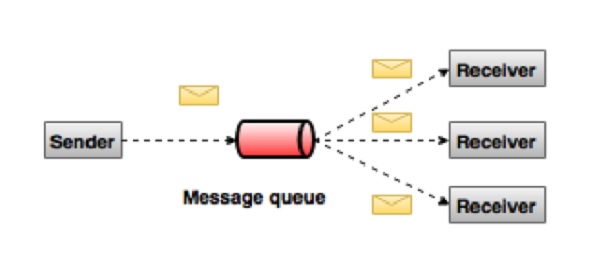
There are two types of messaging systems. The classic example is a point-to-point system where producers persist data to a queue. Then, only one application can read the data from the queue. Once read, the messaging system removes the message from the queue.
Apache Kafka relies upon the publish-subscribe messaging system. Consumers can subscribe to multiple topics in the message queue. Then they receive specific messages that are relevant to their application. The website Tutorialspoint has a useful image that illustrates this.
Broker
As the name suggests, a broker acts as a facilitator between buyer and seller. A Kafka broker receives messages from producers and stores them on its disk. Also, it facilitates message retrieval.
Apache Kafka Architecture
Now, let’s examine the internal Apache Kafka architecture.
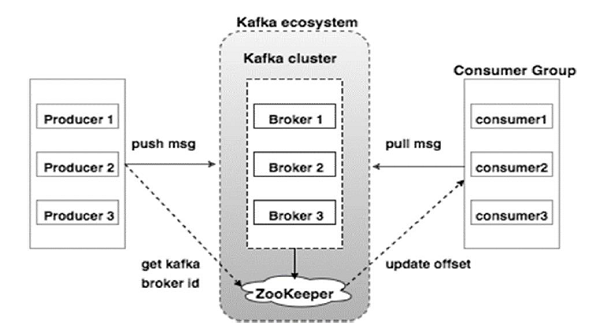
The Kafka ecosystem consists of a producer and a consumer group. For our purposes, the producers and consumers are external actors.
The internal ecosystem includes Kafka’s ZooKeeper service and a Kafka cluster. The ZooKeeper acts as a distributed configuration and synchronization service to manage and coordinate Kafka brokers. ZooKeeper notifies both producers and consumers if a broker is added to or fails in the Kafka system. And finally, ZooKeeper interfaces between Kafka brokers and consumers (see “Brokers” in the terminology section).
The brokers inside the Kafka cluster are responsible for load balancing. To accommodate higher loads, ZooKeeper will initialize more Kafka brokers inside the Kafka cluster. Each broker can read and write thousands of messages. And a single broker can handle terabytes of message data.
Again, Tutorialspoint has a good image that can help you visualize the architecture.
Apache Kafka Use Cases
Next, let’s explore some use cases for Apache Kafka.
Log Aggregation
Kafka can collect the logs of multiple applications and present them as an aggregate. This allows consumers to standardize and analyze logs. Then, important logs can be written to tools like Elasticsearch.
Metrics
Kafka also helps you gather and classify monitoring data. For example, multiple applications can write their monitoring messages to Kafka to create a centralized data feed.
Stream Processing
Stream processing might be the most valuable use for Apache Kafka. It allows consumers to read data from topics, process it, and write it back to a new topic. Then, this data can be consumed by other services which further process the data on their behalf. This approach allows you to process data quickly and efficiently. Additionally, it facilitates a microservices architecture.
Benefits of Apache Kafka
There are four key benefits of using Kafka:
- Reliability: Kafka distributes, replicates, and partitions data. Additionally, Kafka is fault-tolerant.
- Scalability: Kafka’s design allows you to handle enormous volumes of data. And it can scale up without any downtime.
- Durability: Messages received are persisted as quickly as possible to storage. So, we can say Kafka is durable.
- Performance: Finally, Kafka maintains the same level of performance even under extreme loads of data (many terabytes of message data). Kafka can perform up to two million writes per second.
So, you can see that Kafka can large amounts of data with zero downtime and no data loss.
Disadvantages of Apache Kafka
After discussing the advantages, let’s take a look at the disadvantages:
- Limited flexibility: Kafka doesn’t support rich queries. For example, it’s not possible to filter for specific asset data in messages. (Functions like this are the responsibility of the consumer application reading the messages.) With Kafka, you can simply retrieve messages from a particular offset. The messages will be ordered as Kafka received them from the message producer.
- Not designed for holding historical data: Kafka is great for streaming data, but the design doesn’t allow you to store historical data inside Kafka for more than a few hours. Additionally, data is duplicated, which means storage can quickly become expensive for large amounts of data. You should use Kafka as transient storage where data gets consumed as quickly as possible.
- No wildcard topic support: Last on the list of disadvantages is that it’s not possible to consume from multiple topics with one consumer. If you want to consume, for example, both log-2019-01 and log-2019-02, it’s not possible to use a wildcard for topic selection like log-2019-*.
The above disadvantages are design limitations intended to improve Kafka’s performance. For some use cases that expect more flexibility, the above limitations can constrain an application consuming from Kafka.
The Bottom Line
Apache Kafka is a great tool for message queuing. It can handle enormous amounts of message data by scaling the number of available brokers. Also, ZooKeeper makes sure everything is coordinated and remains in sync.
Although there are clear limitations like flexibility, Kafka was designed to be high-performing. Its designers never intended Kafka to offer rich functionality.
Still, if your application handles large amounts of message data, you should consider Apache Kafka for your tech stack.




{kind=link}
{kind=link}