Five Steps to Better Data Quality
If software is eating the world, then it’s data that serves as the calories. Just as there are good calories and bad calories, not all data is equal. As more and more companies use data to drive their decision-making processes, getting good quality data is a crucial ingredient.
You might think data science is a recent thing. But actually, it’s been around since the 1980s, in the form of concepts such as data warehousing. If you scour the internet, looking for advice on getting better data quality, you’ll read about long-standing concepts such as metrics of accuracy and timeliness. In addition, you’ll find more recent tactical advice on how to sanitize data using Python or R. How do we better navigate through this dizzying array of information?
Well, I’m here to help. Here are the five steps you can take today to get better data quality.
Step 1: Define Your Usefulness Metrics
Whether it’s to help management make better decisions faster or to help ground level staff be more responsive, your data has to be useful. Therefore, you have to define what “useful data” looks like.
These are the most common metrics we use to define useful data:
- Accuracy
- Precision
- Completeness
- Validity
- Relevancy
- Timeliness
- Ability to be understood
- Trustworthiness
You can then use these metrics as a checklist to help guide your data quality control:
- Is the level of accuracy acceptable? (Accuracy)
- Is the granularity sufficient? (Precision)
- Have we captured enough data? (Completeness)
- Did we filter out the irrelevant information? (Relevancy)
- Is the data model connecting the data to a sound structure? (Validity)
- Did we run the analysis in batch or in real-time? (Timeliness)
- Did we clean the data up and make it more readable? What about presentation? (Ability to be understood)
- Do we need to do more reconciliation checks? More frequently? Across time? (Trusted)
As a result, you have a wide range of options to define what useful data looks like.
And sometimes less is more. For example, Pinterest realized their new visual AI feature was more useful when they deliberately went for less precision:
That’s the lesson Pinterest learned from avocados. Exact matches are the specialty of Google search, which has been optimized to respond to specific questions–like, “How do you grill fish?”–with the perfect link. Pinterest users tend to pose vaguer queries: They might search for “seafood dinner ideas” several times a week. For them, a non-exact match is not a error. It’s inspiration. — Fast Co. Design article
For users, this imperfect matching is a feature rather than a bug. So you don’t need to have perfect data to have good results. Aim for usefulness, not perfection.
Step 2: Profiling
Profiling means you analyze the information in order to clarify the structure, content, relationships, and derivation rules of the data. This is a crucial step. Users tend to have an understanding, on an intuitive level, of how data is interrelated. Unfortunately, machines currently still need precise instructions. So you need to profile the data at hand and make it work for your users via data analysis software.
Start by clarifying how different data points are related to one another. How do you want to group and structure them? What rules do you want to apply to the data to derive for display purposes? These are the typical steps you apply in data profiling.
But don’t think this is a one-and-done step. Usually, you perform more in-depth profiling before you build your models. After that, you may still continue to perform detailed profiling. That’s because continuous detailed profiling helps determine the appropriate data for extraction and the appropriate filters to apply to your data set.
Sometimes, even after the data loading stage, you may want to continue to perform profiling. This helps ensure that you correctly sanitize the data and transform it to comply with your requirements.
Think of it like this:
If you’re doing it right, the amount of profiling work should decrease over time for your project
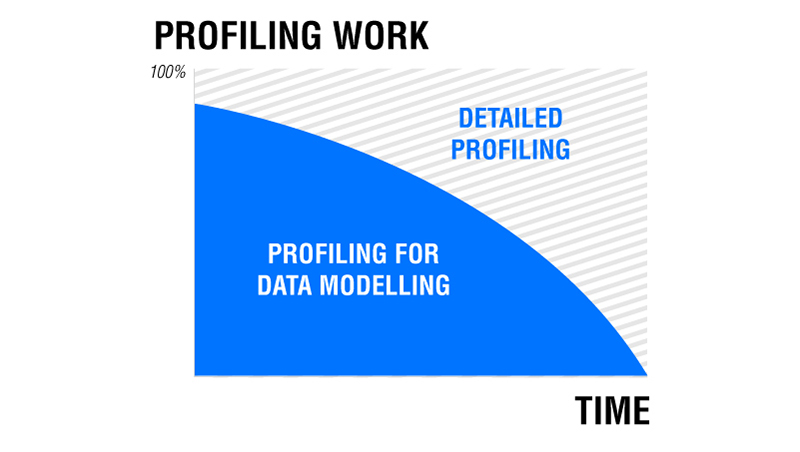
This chart displays how the nature of profiling work changes as the project progresses.
Step 3: Standardization
Setting policies about data standardization is another crucial step for data quality. Standards help improve communications.
Good communication means two different parties can understand one another quickly and completely, with minimal confusion. That’s also true for communicating your data to your audience.
There are two kinds of standardization: external and internal. External standards (as in outside your organization) are appropriate for commonly used data types. For example, if you wanted to represent datetime, you’d choose a widely accepted international standard like ISO-8601. I’d advise you not to invent your own standards needlessly, and don’t choose obscure standards. Remember, your goal is to communicate the data easily and effectively. Therefore, you should choose external standards wisely.
Sometimes, you need to invent your own internal standards. This takes a bit more work, but they’re custom-built to be appropriate for your company’s specific situation. Internal standards also help improve communications in your company. But they might serve another purpose. Imagine your business has a revolutionary business process that allows you to ship twice as fast as your competitors. That’s a huge competitive edge. You’ll want the entire company to work within this revolutionary process and same for the data it uses. To avoid a case of garbage in, garbage out, you might want to ensure that the same vocabulary is consistently applied in the data as well. Consistent internal standards will help your staff stay on the same page and work within the new paradigm you’ve created.
Set Up a Standards Policy Document
Usually, organizations just set up a policy document that contains the standards, and then they’re done with it. That’s not good enough. My experience tells me you’ll want to include the reasons behind the standards themselves. This is helpful because people come and go, but the document remains. Sometimes, these standards may become obsolete or get in the way of the organization achieving its goal in the future.
Compliance and enforcement of standards is another issue. You may want to enlist the help of software. A rules engine is a good way to ensure data is conforming to the standards you’ve put in place. Often, it’s not possible to have all your business rules in one piece of software. You may end up needing several pieces, especially when you have a long and complex process workflow. Therefore, having a single source of truth in a standards policy document can help align your workflow and your various software with the chosen standards.
Step 4: Matching or Linking
So, let’s say that you’ve properly defined what useful data looks like. You’ve performed profiling and your models correctly reflect reality. Standards have been chosen and properly enforced. But what if your audience is still not getting the kind of useful insights they thought they would? This is when you need to add matching and linking capabilities.
Recall that we talked about relationships and the structure of your data earlier, in Step 2: Profiling. You need to show your audience the relationships you discover in your data. When the relationships are in place, your audience will be able to perform a wide array of operations on the data, rolling up, drilling down, and slicing and dicing the data as they need. In other words, they’ll have business intelligence via online analytic processing.
Imagine sales data that’s tied to customers demographics. And imagine it’s tied to product inventory as well. Now have all three disparate data sources all linked together. You’ll have the possibility of anticipating trends and buying patterns based on product, transaction time, or demographics. It’s the same group of data, but it now can be analyzed in three different ways.
Step 5: Monitoring
The work of a good data analyst is never done. You need to constantly monitor the changes in the data you receive and the output you produce. Changes may be brought about by a new competitor in the scene. Or maybe there’s a change in regulation. Technology advances may also cause you to change your data analysis process. Moore’s law never sleeps.
You may have heard that software decays. Data decays, too. New discoveries due to continuous profiling may lead you to change your policy. New standards may need to be introduced.
Constant monitoring of data is crucial. This ensures you don’t accidentally pollute your data warehouse with incorrect or noncompliant data points. You can use software to help alleviate the workload in terms of monitoring. This software will send out notifications to the departments responsible for collecting or sanitizing the data whenever your monitoring software picks up anomalies, such as wrongly inputted data.
What’s Next?
Now that you know the five steps you can take to improve your data quality, check the list again. See which steps highlight an area you need to strengthen. And take note of which steps you’re already doing well. Then, put in place a quarterly review process to make sure you’re continually evaluating your data quality control. This way, you’ll always be seeing where you stand and where you can improve.
Plus, check out our tips for a successful data governance implementation.


